OCR for VINs
Basic Information
The Vehicle Identification Number (VIN) is a string composed of 17 characters, including both digits and uppercase letters. This solution is suitable for optical character recognition (OCR) of VINs. It applies deep learning to detect the location of the VIN and accurately recognize the text.
Solution Workflow
This solution cascades the Text Detection and Text Recognition modules in Mech-DLK. The Text Detection module is used to detect and segment the VINs from the images, and the Text Recognition module is used to recognize and output the VIN text. The following figure shows the workflow for training and deploying the model packages.
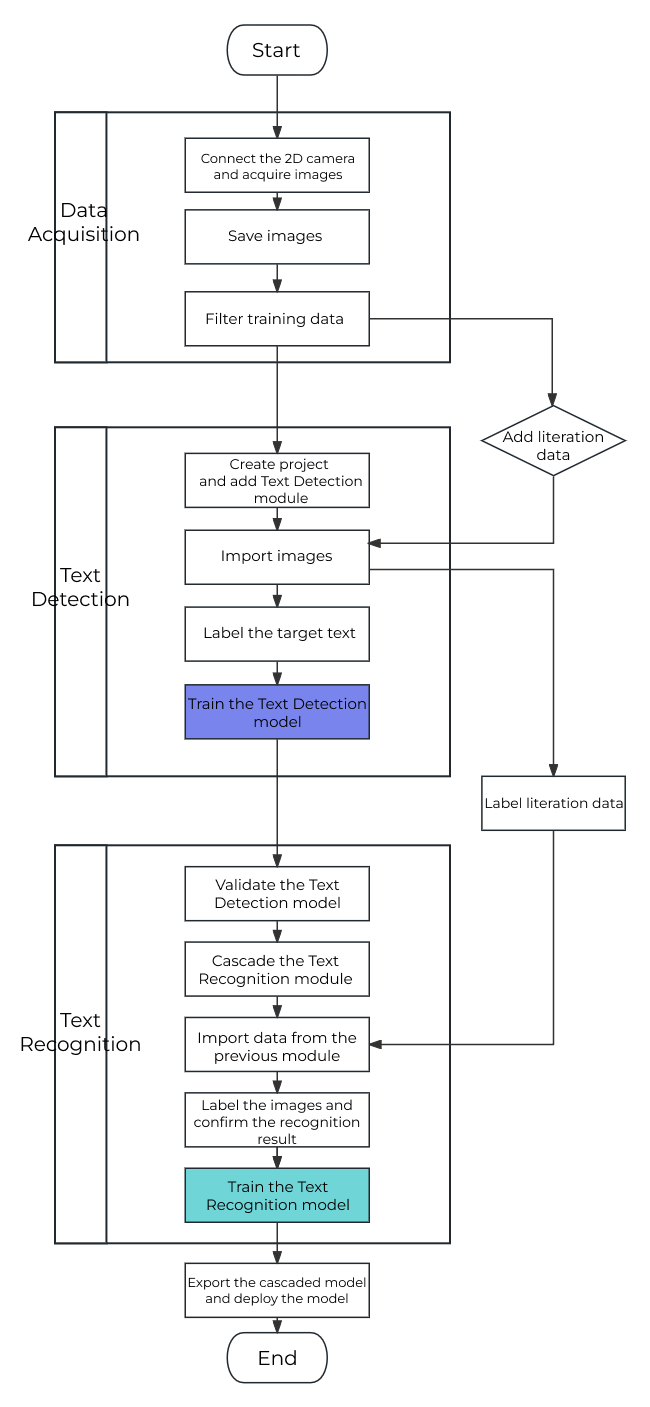
Solution Deployment
Acquire Images
-
Identify all the characters in the VINs to be recognized at the production site, and ensure that the acquired images contain samples of these characters.
-
When acquiring images, all scenarios from the production site must be included. If ambient light, exposure parameters of cameras, or the materials of VIN labels lead to significant differences in image performance, samples from each scenario must be acquired to ensure the acquired images are consistent with the practical applications.
Filter Images
-
Remove images that are obscured by anomalies, overexposed, and underexposed.
-
Sample the data to filter out some duplicate images when a large volume of images is acquired.
-
Ensure an even distribution of images across various scenarios.
The following figure shows an image that is suitable for training.

Train Models
Train a Text Detection Model
-
Create a new project and add the Text Detection module: Click New Project after you opened the software, name the project, and select a directory to save the project. Then, click + in the upper-right corner and add the Text Detection module.
-
Import image data: In the upper-left corner, click and import the image folder that contains the acquired VIN images.
-
Label the images: Select the Free Rectangle Tool
 from the labeling toolbar to label the images. During labeling, the selection frame should be placed as close to the edges of the text area as possible to minimize interference.
from the labeling toolbar to label the images. During labeling, the selection frame should be placed as close to the edges of the text area as possible to minimize interference.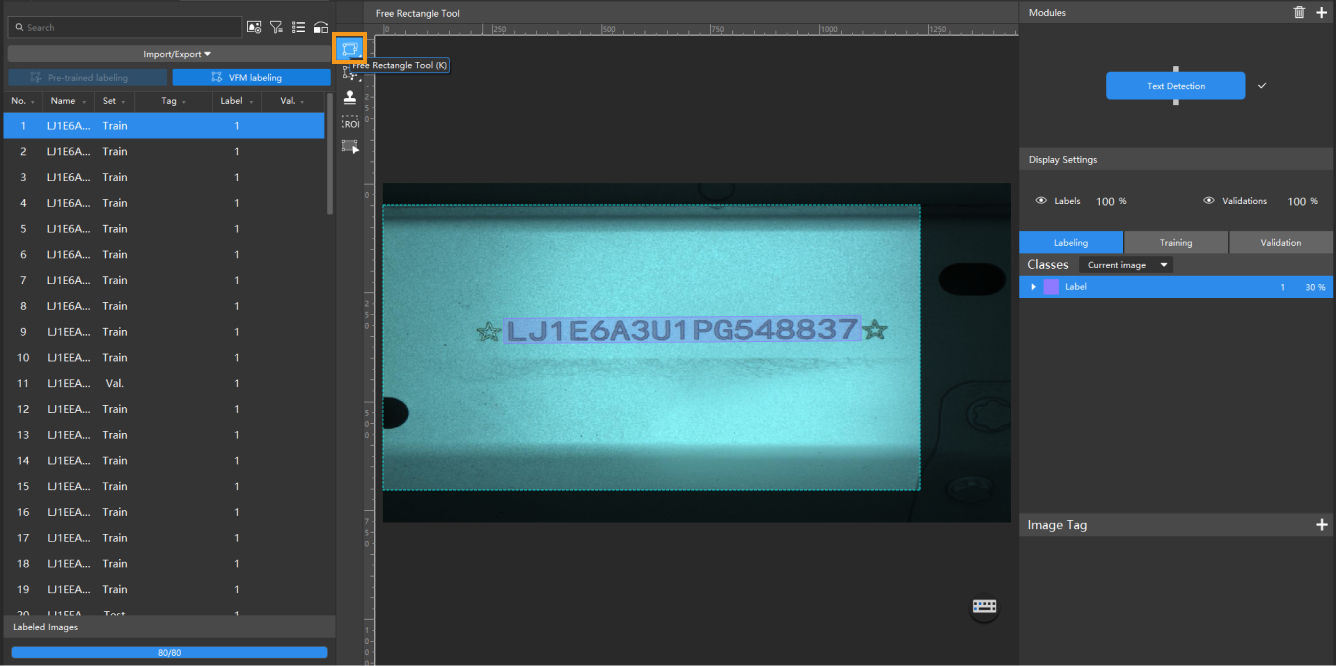
-
Train the model: After all images are labeled, in the Training tab, keep the default training parameter settings and click Train to start training the model.
-
Validate the model: After the training is completed, in the Validation tab, click Validate to validate the model and check the results.
Train a Text Recognition Model
-
Cascade a Text Recognition module: Click + in the upper-right corner, select the Text Recognition module, and cascade it after the Text Detection module.
-
Import image data: In the upper-left corner, click , select all validation results from the previous module, and enable the Rectify image(s) function to rectify images to 0°.
-
Label the images: Select the Text Recognition Tool
 from the labeling toolbar to label the images. When the Text Recognition Tool is used to make a selection, the recognition result will automatically appear right under the selection frame. Manual verification and confirmation are required. If the recognition result is incorrect, correct the result first and then click the OK button.
from the labeling toolbar to label the images. When the Text Recognition Tool is used to make a selection, the recognition result will automatically appear right under the selection frame. Manual verification and confirmation are required. If the recognition result is incorrect, correct the result first and then click the OK button.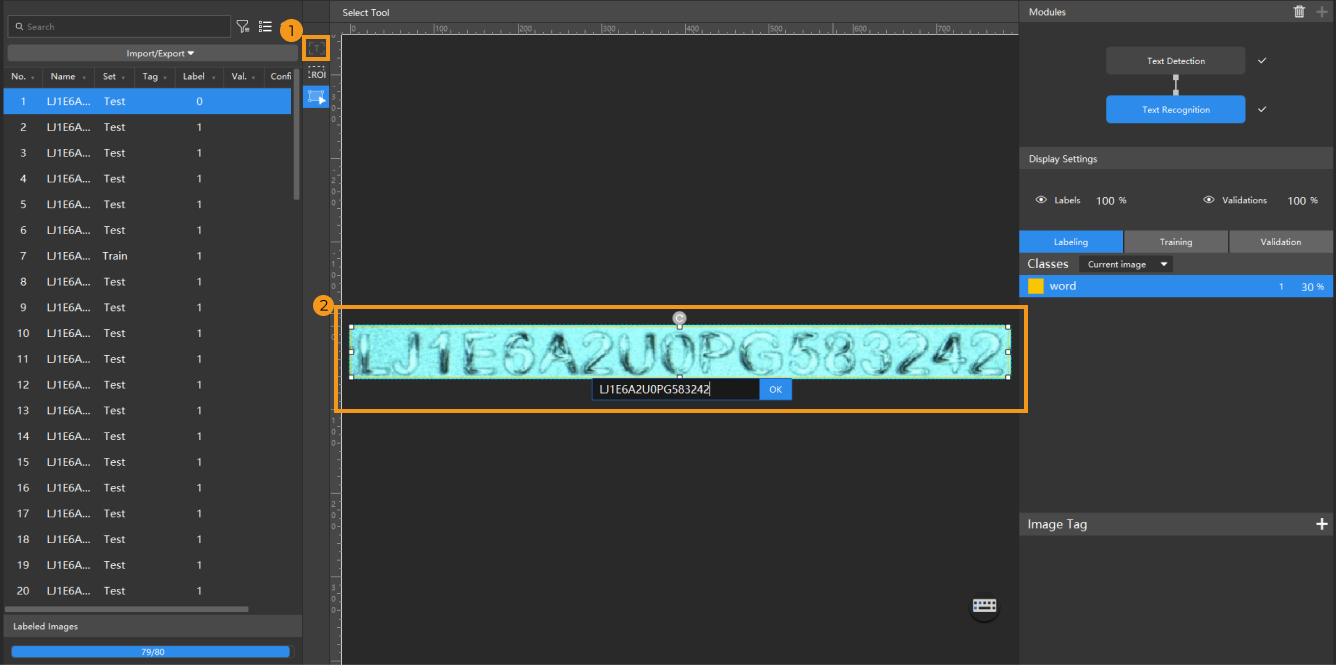
-
Train the model: After all images are labeled, in the Training tab, keep the default training parameter settings and click Train to start training the model.
-
Validate the model: After the training is completed, in the Validation tab, click Validate to validate the model and check the results.
Deploy Models
You can use Mech-DLK SDK for secondary development to integrate deep learning inference functions into the quality control system (software) of the production line. Then, use the exported model packages for inference to obtain the inference results.
| The exported model can be used in the Deep Learning Model Package Inference Step and the Deep Learning Result Parser Step in Mech-Vision. The Deep Learning Model Package Inference Step performs model inference with cascaded model packages and outputs the inference results. The Deep Learning Result Parser Step follows the Deep Learning Model Package Inference Step, and can parse the exported inference results. In this solution, you only need to parse the Text Recognition Result. To use Mech-Vision, a corresponding software license must be purchased. |
Iterate Models
If the models perform poorly due to new characters to be recognized at the production site or other factors, the models need to be iterated.
-
Acquire iteration data: Acquire images that contain new characters and images that report poor recognition results for model iteration.
-
Import iteration data: In the Text Detection module, click , and import the folder that contains the iteration data.
-
Tag the images: In the Labeling tab, click + to create a tag named Iteration Data and tag the newly added images.
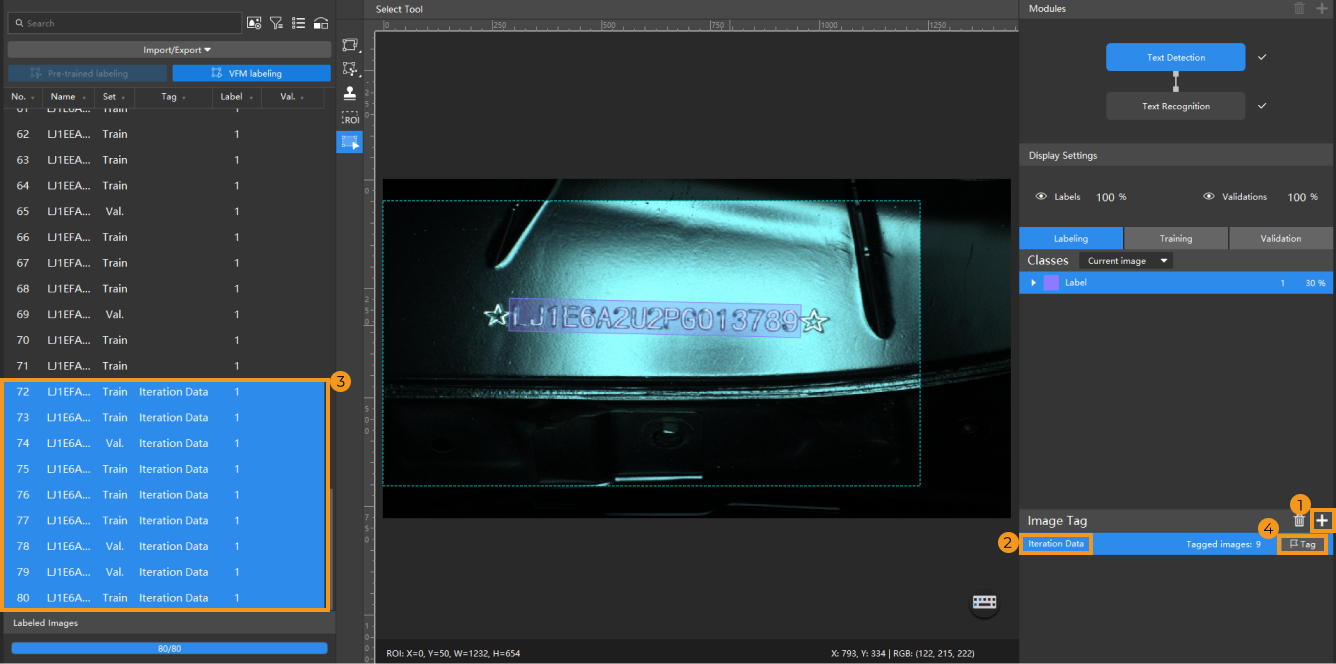
-
Label the images: Label the newly added images.
-
Iterate the Text Detection model: In the menu bar, click , and enable Developer mode. In the Training tab, click , and enable Finetune.
-
Train the iterated model: Click Train to train the iterated model.
After the iterated Text Detection model is validated, switch to the Text Recognition module. Click , select the Iteration Data tag from the Image tag drop-down list, and import all selected images. Then, follow the same steps to iterate the Text Recognition model and validate the results.