
使用深度学习
本节介绍深度学习工作流程,整体工作流程如下图所示。

-
准备工作:训练模型前需进行相关准备工作,如图像数据采集、工控机选型等。
-
训练模型:准备工作就绪后,即可利用准备好的数据在Mech-DLK中进行模型训练和验证。
-
配置并使用模型:模型训练完成后,需在Mech-Vision中对模型进行配置,然后在相关步骤中使用该模型完成相关任务。
-
迭代模型:在模型使用一段时间后,若发现该模型不能覆盖部分场景,需对模型进行迭代。
准备工作
准备工控机
使用Mech-DLK训练深度学习模型时,对工控机配置有一定的要求,建议满足以下要求。
软件许可授权版本 |
Pro-Run |
Pro-Train/Standard |
|---|---|---|
操作系统 |
Windows 10 及以上 |
|
CPU |
Intel® Core™ i7-6700 及以上 |
|
内存 |
8 GB 及以上 |
16 GB 及以上 |
显卡 |
GeForce GTX 1660 及以上 |
GeForce RTX 3060 及以上 |
显卡驱动 |
驱动版本 472.50 及以上 |
|
|
Pro-Run 版本具有Mech-DLK SDK部署、标注、运行模式功能;Pro-Train 版本具有级联、标注、训练、验证以及Mech-DLK SDK部署功能;Standard 版本具有标注、训练、验证功能。 |
搭建图像采集工程
准备好工控机后,即可开始搭建图像采集工程。无需搭建专门的图像采集工程,使用根据实际业务需求搭建的视觉工程即可完成图像采集。
视觉工程搭建完成后,为了在运行工程时将图像保存至指定位置,需开启 数据保存 功能。
-
进入数据保存界面。在Mech-Vision工程配置区底部单击工程助手,然后单击
 ,进入数据保存界面。
,进入数据保存界面。 -
开启数据保存功能。在数据保存界面中开启保存数据与参数。
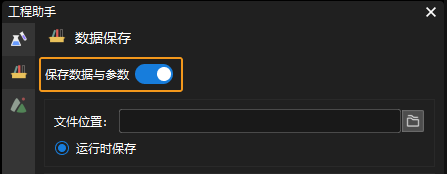
-
设置图像保存路径。在数据保存界面中设置文件位置,用于保存采集到的图像数据,一般情况下,需将图像数据保存至工程文件夹下的 data 文件夹中。
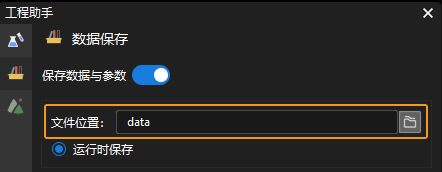
采集图像数据
视觉工程搭建并部署完成后,即可开始采集图像数据。
保证图像质量(采集前)
图像质量决定着模型的稳定程度,高质量的图像数据往往可以提高模型识别效果、预测的准确性。所以在图像数据采集前,需对相机的白平衡和 2D 曝光参数进行调整,并确保采集的图像是完整的、未被裁剪的。
调整白平衡
白平衡指的是在图像中校正不同光源条件下的颜色偏差,确保白色在图像中看起来是真实的白色。
如果使用颜色失真的 2D 图训练深度学习模型,其中的颜色偏差会被当做物体特征用于训练,从而影响后续模型表现。所以为了获得白平衡正常的图像数据,在采集数据前需调节白平衡,具体方法可参考 调节白平衡 。
调整曝光参数
模型训练时,图像中目标物体的各种特征都会被提取,如颜色信息、轮廓形状信息等。当图像出现过曝、过暗的情况时,上述特征信息会或多或少的丢失,导致模型训练时无法学习到关键信息,影响后续模型表现。所以为了获得高质量的图像数据,在采集数据前需调节相机曝光参数,具体方法可参考 调整相机曝光参数 。
保证图像数量(采集时)
图像数据采集时,需要采集足够数量的图像,并保证图像种类具有多样性,用于训练模型。需注意不同类型的工件有不同的图像采集数量要求。
为了保证采集的图像种类具有多样性,通常采用人工触发工程运行的方式来采集图像,每运行一次工程,需人为调整工件的位置和摆放方式。
|
刚性工件指的是在运动和受力后,形状和大小不变,且内部各点的相对位置不变的工件。 |
单击此处查看不同情况下刚性工件图像采集数量要求。
| 单品类工件 | 多品类(来料无混料)工件 | 多品类(来料有混料)工件 | 多面体工件 | |
|---|---|---|---|---|
整齐来料时的图像采集数量 |
40~60 张 |
40~60 张 |
60~80 张 |
80~100 张 |
散乱来料时的图像采集图像数量 |
60~80 张 |
每种工件分别单独采集 40~60 张 |
100 张 |
100~120 张 |
同时需要注意,采集的刚性工件图像应该包含多个工位、并且包含不同朝向、包含不同疏密程度、体现不同高度、包含不同光照情况。
单击此处查看不同情况下麻袋类工件图像采集数量要求。
| 麻袋被装填满,且堆叠整齐 | 麻袋被装松散,且表面褶皱较多 | |
|---|---|---|
图像采集数量 |
20 张 |
30 张 |
同时需要注意,采集的麻袋类工件图像应该包含不同种类/层数的麻袋、体现麻袋的不同摆放/来料方式/垛型、包含不同光照情况。
单击此处查看不同情况下纸箱类工件图像采集数量要求。
| 单品类纸箱 | 多品类(混料)纸箱 | 散乱摆放的纸箱 | 特殊情形的纸箱(贴有胶带、标签,或绑有轧带) | |
|---|---|---|---|---|
图像采集数量 |
从最高层至空垛,共需采集 30 张图像。 |
每个类别的纸箱,需分别采集 20 张图像。 |
需采集 50 张图像。 若纸箱表面有图案,需采集 60 张图像; 若需区分纸箱类别,需采集 70 张图像。 |
50 张 |
同时需要注意,采集的纸箱类工件图像应该包含不同种类/层数的纸箱、体现纸箱的不同摆放/来料方式/垛型、包含不同光照情况。
筛选图像(采集后)
图像数据采集完成后,需对图像进行筛选,剔除低质量图像,保留高质量图像,并保证图像种类多样性。
单击此处查看刚性工件、麻袋/纸箱类工件图像筛选要求。
| 哪些图像需被筛除 | 哪些图像需被保留 | |
|---|---|---|
刚性工件 |
|
|
纸箱、麻袋类工件 |
|
|
训练模型
上述准备工作完成后,即可利用采集到的图像在Mech-DLK中训练模型,模型训练流程如下图所示。

-
新建工程:建立用于训练模型的工程。
-
选择算法:根据实际需求选择想要使用的深度学习算法模块。
-
导入图像:导入采集完成的图像数据,用于训练模型。
-
标注图像:对图像特征进行标注,提供模型训练所需的信息。
-
训练模型:利用选择好的深度学习算法模块,对标注完成的图像进行模型训练。
-
验证模型:模型训练完成后,对模型进行验证并查看模型效果。
-
导出模型:模型效果确认无误后,以模型包的形式导出模型至指定位置。
详细操作过程可参考 实例分割模型训练 。
配置并使用模型
获得模型包后,需在Mech-Vision中进行配置,然后在相关步骤中使用该模型包进行推理。详细操作过程可参考 深度学习模型包管理工具操作指南 。
迭代模型
在模型使用一段时间后,若发现模型不能覆盖某些场景,此时需对模型进行迭代。传统的方案是增加数据重新训练,但可能会降低整体识别准确率,同时花费时间较长。建议使用“模型微调”的方式对模型迭代,既能保持模型准确率,也能节省时间。详细操作过程可参考 深度学习模型迭代 。
上述流程完成后,可根据以下视频教程对实例分割模型训练与使用进行实践。